티스토리 뷰
1️⃣ 한국어 자연어 처리
▶ 자연어 처리의 기본 요소
- 자연어 처리의 기본은 단어 추출에서 시작
- 텍스트의 단어를 통해 문장의 의미, 구성 요소 및 특징을 파악 가능


▶ 한국어에서의 단어
- 한국어에서 단어의 기준은 명확하지 않다.

- 교착어인 한국어에서 단어는 의미적 기능을 하는 부분과 문법적인 기능을 하는 부분의 조합으로 구성된다.

→ 한국어 자연어 처리에서는 단어의 의미적 기능과 문법적인 기능을 구분하는 것이 중요
2️⃣ KoNLPy
▶ 형태소 분석
형태소 분석이란 ?
: 주어진 한국어 텍스트를 단어의 원형 형태로 분리해 주는 작업

▶ KoNLPy
: 여러 한국어 형태소 사전을 기반으로 한국어 단어를 추출해 주는 파이썬 라이브러리

- 각 형태소 사전별 형태소 표기 방법 및 기준의 차이가 존재한다.

각 형태소 분석기 호출 방식
Hannanum( )Kkma( )Komoran(userdict=로컬경로)Mecab( )Okt( )
꼬꼬마 (kkma)를 통한 전처리
from konlpy.tag import Kkma
# 예시 문장
sent = "안녕 나는 엘리스야 반가워. 너의 이름은 뭐야?"
# 객체 생성
kkma = Kkma()
# 명사 추출
print(kkma.nouns(sent)) # ['안녕', '나', '엘리스', '너', '이름', '뭐']
# 형태소 분석 (단어의 원형 형태, 형태소 정보 반환)
print(kkma.pos(sent)) # [('안녕', 'NNG'), ('나', 'NP'), ('는', 'JX'), ('엘리스', 'NNG'), ('야', 'JX'), ...
# 문장 구분 (리스트로 반환)
print(kkma.sentences(sent)) # ['안녕 나는 엘리스야 반가워.', '너의 이름은 뭐야?']
Okt를 통한 전처리
from konlpy.tag import Okt
sent = "안녕 나는 엘리스야 반가워. 너의 이름은 뭐야?"
# 객체 생성
okt = Okt()
# 명사 추출
print(okt.nouns(sent)) # ['안녕', '나', '엘리스', '너', '이름', '뭐']
# 형태소 분석
print(okt.pos(sent)) # [('안녕', 'Noun'), ('나', 'Noun'), ('는', 'Josa'), ('엘리스', 'Noun'), ...
# stemming (원형형태 반환)
print(okt.pos(sent, stem = True)) # ... ('반갑다', 'Adjective') ...
3️⃣ soynlp
사전 기반의 단어 처리의 경우
- 미등록 단어 문제가 발생할 수 있다.
- 형태소 분석기 종류에 따라 결과가 다를 수 있다.
보코하람 테러로 소말리아에서 전쟁이 있었어요→ 꼬꼬마 기준 추출된 명사 : [보, 보코, 코, 테러, 소말리, 전쟁]
→ OKT 기준 추출된 명사 : [보코하람, 테러, 소말리아, 전쟁]
▶ soynlp
soynlp는 학습 데이터 내 자주 발생하는 패턴을 기반으로 단어의 경계선을 구분한다.
→ 한국어 단어 추출 중 발생할 수 있는 미등록 단어 문제를 해결 가능

soynlp 가정 1 : 단어는 연속으로 등장하는 글자의 조합이며 글자 간 연관성이 높다고 가정한다.
보코하람 테러로 소말리아에서 전쟁이 있었어요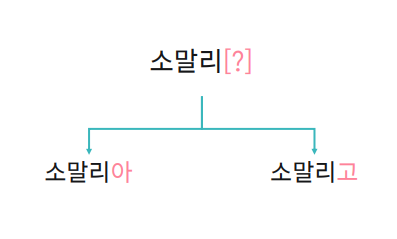
soynlp 가정 2 : 한국어의 어절은 좌 – 우 구조로 2등분 할 수 있다.

soynlp 사용하기
from soynlp.utils import DoublespaceLineCorpus
from soynlp.word import WordExtractor
from soynlp.noun import LRNounExtractor_v2
train_data = DoublespaceLineCorpus(학습데이터의 경로) # 데이터 기반 패턴 학습
noun_extractor = LRNounExtractor_v2()
nouns = noun_extractor.train_extract(train_data) # [할리우드, 모바일게임 ...
word_extractor = WordExtractor()
words = word_extractor.train_extract(train_data) # [클린턴, 트럼프, 프로그램 ...
- soynlp는 학습 데이터를 기반으로 단어 추출 기준, 명사 추출 기준을 직접 학습한다.
(사전으로 잘 학습되지 않는 단어들을 추출해야될 때 사용)
- KoNLPy와 soynlp를 혼용해서 사용하면 더 효과적인 텍스트 전처리가 가능하다.
4️⃣ 문장 유사도
문장 간 유사도는 공통된 단어 혹은 의미를 기반으로 계산한다.
[문장 1] 오늘은 중부지방을 중심으로 소나기가 예상됩니다.
[문장 2] 오늘은 전국이 맑은 날씨가 예상됩니다.
[문장 3] 앞으로 접종 속도는 빨라질 것으로 예상됩니다
▶ 자카드 지수

자카드(Jaccard) 지수
: 문장 간 공통된 단어의 비율로 문장 간 유사도를 측정
- 문장 간 유사도를 0 ~ 1 사이로 정의한다.
- 단어 기준으로 유사도를 비교하기 때문에 의미적인 내용은 부여하기에 어려움이 있다. (정확도 떨어짐)
[예시]

▶ 코사인 유사도

코사인 유사도
: 문장 벡터 간의 각도를 기반으로 유사도를 계산
- 벡터 간의 각도는 벡터 간 내적을 사용해서 계산한다.
- 유클리드 거리와 같은 다양한 거리 지표가 존재한다.
- 코사인 유사도는 고차원의 공간에서 벡터 간의 유사성을 잘 보존하는 장점이 있다.
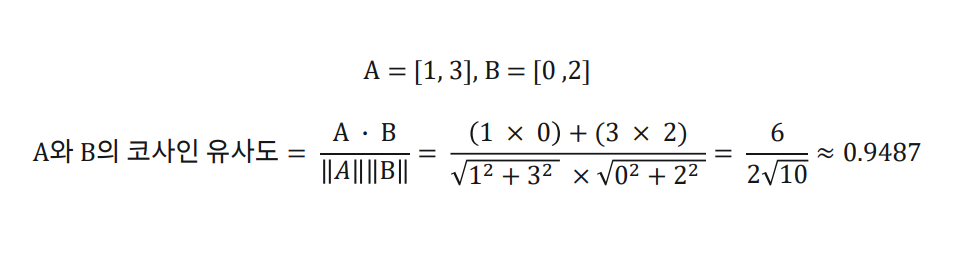
💡 유클리드 거리
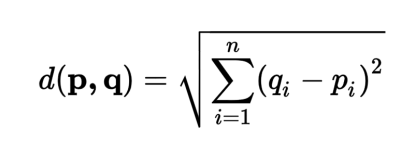

이 글은 엘리스의 AI트랙 5기 강의를 들으며 정리한 내용입니다.
'개발공부 > 🤖 DL & ML' 카테고리의 다른 글
| [RNN] LSTM과 GRU (0) | 2022.11.10 |
|---|---|
| [딥러닝 활용] 모델 서비스하기 (0) | 2022.11.09 |
| [RNN] Recurrent Neural Network (0) | 2022.11.07 |
| [자연어 처리] 텍스트 전처리 및 단어 임베딩 (0) | 2022.11.03 |
| [CNN] Convolutional Neural Network (0) | 2022.11.02 |

프론트엔드 개발자 삐롱히의 개발 & 공부 기록 블로그