티스토리 뷰
1️⃣ 자연어 처리
▶ 자연어 처리 란?
자연어 처리(Natural Language Processing, NLP)는 컴퓨터를 통해 인간의 언어를 분석 및 처리하는 인공지능의 한 분야
자연어 처리의 적용 사례
문서분류, 키워드 추출, 감정 분석, ...

학습 가능한 데이터양의 증가 및 연산 처리 속도의 발전으로 자연어 처리 또한 더욱 복잡한 머신러닝 알고리즘 적용 가능
→ 자연어 처리 + 머신러닝
머신러닝 기반 자연어 처리의 적용 사례
문서 요약, 기계 번역, 챗봇, ...

2️⃣ 텍스트 전처리
▶ 모델링을 위한 데이터 탐색 및 전처리
데이터 전처리를 하는 이유
→ 모델이 좀 더 효과적이고 효율적으로 작동하기 위해
→ GIGO (Garbage In, Garbage Out)
데이터 탐색
- 데이터 통계치 ex) 단어의 개수
- 변수별 특징 ex) 단어별 빈도수
- ...
데이터 전처리
- 이상치 제거 ex) 특수기호 제거
- 정규화 (Normalization) ex) 단어 정규화
- ...
▶ Tokenization (토큰화)
토큰화는 주어진 텍스트를 각 단어 기준으로 분리하는 것을 의미한다.
분리된 각각의 단어를 토큰이라고 한다.
- 가장 기본적인 토큰화의 기준은 공백
- 소문자 처리 및 특수기호 제거를 통해 동일한 의미의 토큰은 동일한 형태로 변환

단어의 개수 및 빈도수 확인
counter = dict()
with open(파일명, 'r') as f:
for line in f:
for word in line.rstrip().split(): # 줄바꿈 기호 제거 rstrip()
if word not in word_counter:
word_counter[word] = 1
else:
word_counter[word] += 1
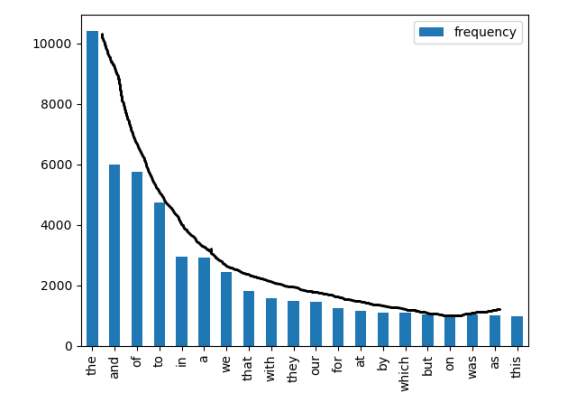
- 대부분 단어 빈도수의 분포는 지프의 법칙(Zipf's law)을 따른다.
전처리 1) 특수 기호 제거
모든 텍스트 분석에 앞서 텍스트 안에 어떠한 단어가 존재하는지 살펴보는 것이 중요
→ 하지만 동일한 의미를 가진 단어를 여러 방식으로 표현하여 사용하기 때문에 단순히 텍스트를
공백 기준으로 나눠 단어를 추출하면 여러 가지 문제점이 발생
ex) computer가 문장 내 위치에 따라 Computer와 같이 대문자로 표기하거나 computer!와 같이 특수기호와 함께 표기
import re
word = "123hello993 $!%eli$@ce^"
regex = re.compile('[^a-z A-Z]')
print(regex.sub('', word)) # word변수에 해당하는 문자열에서 regex에 해당하지 않는 문자는 공백으로 치환
# hello elice- re : 정규표현식 라이브러리
💡 정규표현식
: 정의하는 규칙을 가진 문자열 집합
전처리 2) Stopword 제거
문법적인 기능을 지닌 단어 및 불필요하게 자주 발생하는 단어를 제거한다.

import nltk
from nltk.corpus import stopwords
sentence = ["the", "green", "egg", "and", "ham", "a", "an"]
stopwords = stopwords.words('english') # 리스트를 반환
new_sentence = [word for word in sentence if word not in stopwords]
print(new_sentence)
# ["green", "egg", "ham"]- nltk : 텍스트 전처리 및 탐색 코드를 보다 빠르고 간편하게 작성할 수 있게 도와주는 Python 라이브러리
- nltk의 stopwords안에 이미 정의된 stopword들이 있다.
import nltk
from nltk.corpus import stopwords
new_stopwords = ["none", "는", "가"] # 신규 stopword
stopwords = stopwords.words('English') # 리스트를 반환
stopwords += new_stopwords- 원하는 stopword를 추가할 수도 있다.
전처리 3) Stemming
동일한 의미의 단어이지만, 문법적인 이유 등 표현 방식이 다양한 단어를 공통된 형태로 변환한다.

import nltk
from nltk.stem import PorterStemmer
words = ["studies", "studied", "studying", "dogs", "dog"]
stemmer = PorterStemmer()
for word in words:
print(stemmer.stem(word)) # studi, studi, studi, dog, dog
3️⃣ 단어 임베딩
컴퓨터는 텍스트를 포함하여 모든 데이터를 0과 1로 처리
→ 자연어의 기본 단위인 단어를 수치형 데이터로 표현하는 것이 중요
▶ 단어 임베딩
: 각 단어를 연속형 벡터로 표현하는 방법
(임베딩의 목적은 단어를 벡터로 표현하는 것)

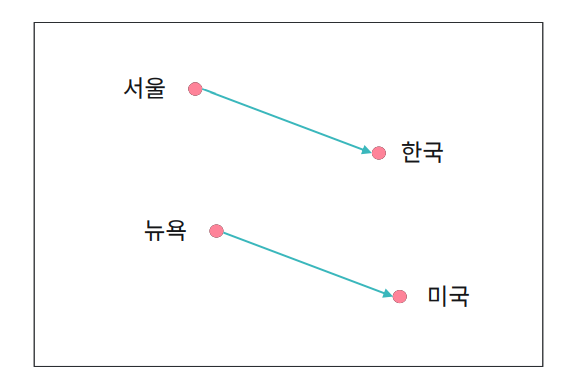
- 비슷한 문맥에서 발생하는 단어는 유사한 의미를 지닌다.
ex)
서울에 살고 있는 엘리스는 강아지를 좋아한다.
뉴욕에 살고 있는 찰리는 고양이를 좋아한다.
- 유사한 단어의 임베딩 벡터는 인접한 공간에 위치한다.

- 임베딩 벡터 간 합과 차로 단어의 의미적 특징을 활용 가능하다.
4️⃣ word2vec
▶ word2vec
: 단일 신경망(Neural Netword)을 통해 단어 임베딩 벡터를 학습
- 주어진 문맥에서 발생하는 단어를 예측하는 문제로 통해 단어 임베딩 벡터를 학습한다.
- 각 단어의 벡터는 해당 단어가 입력으로 주어졌을 때 계산되는 은닉층의 값을 사용한다.
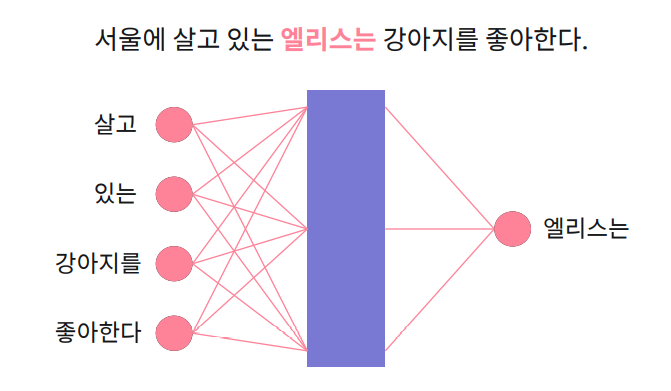
ex) 살고, 있는, 강이지를, 좋아한다라는 문맥이 입력값으로 주어지면 "엘리스는"이라는 단어를 예측
from gensim.models import Word2Vec
doc = [["서울에", "살고", "있는", "엘리스는", "강아지를","좋아한다"]]
w2v_model = Word2Vec(min_count=1, window=2, vector_size=300)
w2v_model.build_vocab(doc)
w2v_model.train(doc, total_examples=w2v_model.corpus_count, epochs=20)- min_count : min_count보다 적게 발생하는 단어들은 학습하지 않는다. ex) min_count=1 이면 모든 단어를 학습
- window : 문맥의 범위 ex) "엘리스는" 단어를 기준으로 앞 2개, 뒤 2개 (살고, 있는, 강아지를, 좋아한다)를 입력값으로 사용
- vector_size : 임베딩 벡터의 차원 수 (= 은닉층의 노드의 갯수)
- .build_vocab(data) : 학습 데이터에 있는 단어에 각각 특정 정수 인덱스를 부여 (단어를 효율적으로 처리, 보존하기 위해)
- .corpus_count : w2v객체에서 build_vocab()할 때 사용되는 학습데이터 안의 총 문서의 갯수를 자동으로 측정
# 학습이 끝나면
similar_word = w2v_model.wv.most_similar("엘리스는")
print(similar_word)
# [('있는', 0.05005083233118057), ('좋아한다', 0.03316839784383774),
('강아지를', 0.025744464248418808), ('서울에', 0.013042463921010494),
('살고', -0.0342760793864727)]
score = w2v_model.wv.similarity("엘리스는", "좋아한다")
print(score)
# 0.03316839784383774- w2v객체.wv.most_similar("단어") : "단어"의 임베딩 벡터를 활용해서 가장 유사한 단어들을 반환
- w2v객체.wv.similarity("단어1", "단어2") : 각각의 임베딩 벡터를 활용해서 두 단어가 얼마나 유사한지 유사도를 반환
5️⃣ fastText
word2vec은 주어지는 문맥을 통해 단어를 예측
→ 학습 데이터 내 존재하지 않았던 단어 벡터는 생성할 수 없다. (미등록 단어 문제, out-of-vocabulary)
▶ fastText
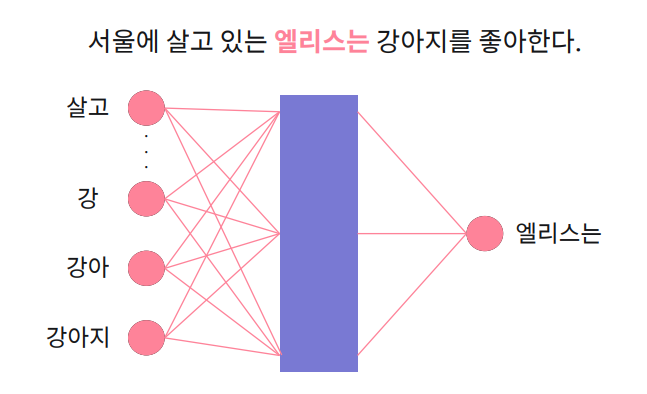
: 각 단어를 문자 단위로 나누어서 단어 임베딩 벡터를 학습
- 각 단어를 문자 단위로 나누어서 단어 임베딩 벡터를 학습한다.
- 학습 데이터에 존재하지 않았던 단어의 임베딩 벡터 또한 생성 가능하다.

from gensim.models import FastText
doc = [["서울에", "살고", "있는", "엘리스는", "강아지를","좋아한다"]]
ft_model = FastText(min_count=1, window=2, vector_size=300)
ft_model.build_vocab(doc)
ft_model.train(doc, total_examples=ft_model.corpus_count, epochs=20)similar_word = ft_model.wv.most_similar("엘리스는")
print(similar_word)
# [('좋아한다', 0.03110547922551632), ('살고', 0.015657681971788406),
('강아지를', -0.09297232329845428), ('서울에', -0.10255782306194305),
('있는', -0.10588616132736206)]
new_vector = ft_model.wv["좋아한다고"]
print(new_vector)
# array([-5.8544584e-04, -1.5485507e-03, -1.3994898e-03, -9.1309723e-04, ...- w2v 사용법과 거의 동일
- fastText객체.wv["새로운단어"] : 학습데이터에 존재하지 않았던 단어에 대한 임베딩 벡터 추정

이 글은 엘리스의 AI트랙 5기 강의를 들으며 정리한 내용입니다.
'개발공부 > 🤖 DL & ML' 카테고리의 다른 글
| [딥러닝 활용] 모델 서비스하기 (0) | 2022.11.09 |
|---|---|
| [RNN] Recurrent Neural Network (0) | 2022.11.07 |
| [CNN] Convolutional Neural Network (0) | 2022.11.02 |
| [CNN] 이미지 데이터 (0) | 2022.11.01 |
| [딥러닝 기초] 딥러닝 모델 학습의 문제점 (0) | 2022.11.01 |

프론트엔드 개발자 삐롱히의 개발 & 공부 기록 블로그