티스토리 뷰
1️⃣ 순차 데이터란?
▶ RNN과 순차 데이터
- RNN(Recurrent Neural Network)은 CNN과 함께 대표적인 딥러닝 모델
- 시계열 데이터 같은 순차 데이터(Sequential Data) 처리를 위한 모델
RNN의 이해에는 순차 데이터가 가지는 특징의 이해가 필요하다.

순차 데이터
- 순서(Order)를 가지고 나타나는 데이터
- 데이터 내 각 개체 간의 순서가 중요
- 날짜에 따른 기온 데이터나 단어들로 이루어진 문장 등

순차 데이터 종류
1) 시계열 데이터 (Time-Series Data)
- 일정한 시간 간격을 가지고 얻어낸 데이터
ex) 연도별 대한민국의 평균 기온, 시간별 주식 가격 기록 등

2) 자연어 데이터 (Natural Language)
- 인류가 말하는 언어를 의미
- 주로 문장 내에서 단어가 등장하는 순서에 주목

2️⃣ 딥러닝을 활용한 순차 데이터 처리 예시
▶ 경향성 파악
주가 예측, 기온 예측, 이외에도 다양한 시계열 특징을 가지는 데이터에 적용 가능

▶ 음악 장르 분석
- 오디오 파일은 본질적으로 시계열 데이터
- 음파 형태 등을 분석하여 오디오 파일의 장르 분석

▶ 강수량 예측 (Precipitation Forecasting)
구글에서 이미지 처리 기술과 결합하여 주도적으로 연구
ex) MetNet

▶ 음성 인식 (Speech Recognition)
음성에 포함된 단어나 소리를 추출
ex) Apple Siri, Google Assistant
▶ 번역기 (Translator)
- 두 언어 간 문장 번역을 수행
- 딥러닝의 발전 이후 번역의 자연스러움 향상
- 이미지 처리와 결합하여 실시간 번역도 제공
ex) 구글 번역, 네이버 파파고 등

▶ 챗봇 (Chatbot)
- 사용자의 질문에 사람처럼 응답하고자 하는 프로그램
- 사용자의 질문을 분석 후 질문에 적절한 응답 생성
3️⃣ Recurrent Neural Network (RNN)
▶ Fully-connected Layer와 순차 데이터

1) FC Layer는 입력 노드 개수와 출력 노드 개수가 정해진다.
→ 순차 데이터는 하나의 데이터를 이루는 개체 수가 다를 수 있다. (문장은 모두 서로 다른 개수의 단어로 이루어진다)
2) FC Layer는 순서를 고려하는 것이 불가능하다.
따라서, 순차 데이터 처리를 위한 딥러닝 모델 등장 : Recurrent Neural Network
RNN의 대표적인 구성 요소
- Hidden State : 순환 구조를 구현하는 핵심 장치

▶ 입력 데이터 구조

- 𝑥1, 𝑥2, 𝑥3, … , 𝑥𝑛과 같이 데이터의 나열
각 𝑥𝑡의 의미는
- 시계열 데이터에서는 "일정 시간 간격으로 나눠진 데이터 개체 하나"
- 자연어 데이터에서는 "문장 내의 각 단어"
▶ 시계열 데이터의 벡터 변환
- 입력 데이터의 각 𝑥𝑡는 벡터 형태
- 시계열 데이터의 경우, 각 데이터를 이루는 Feature 값들을 원소로 하여 벡터로 변환

▶ 자연어 데이터의 벡터 변환
- 각 단어들을 숫자로 이루어진 벡터로 변환 → 임베딩(Embedding)
- 대표적인 임베딩 기법 : One-hot Encoding, Word2Vec, ...

4️⃣ Vanilla RNN
- 가장 간단한 형태의 RNN 모델 (= Simple RNN)
- 내부에 세개의 FC Layer(Fully-connected Layer) 로 구성
| 𝑊ℎℎ | hidden state(𝒉𝒕−𝟏)를 변환하는 Layer의 가중치 행렬 |
| 𝑊𝑥ℎ | 한 시점의 입력값 (𝒙𝒕 ) 을 변환하는 Layer의 가중치 행렬 |
| 𝑊ℎ𝑦 | 한 시점의 출력값 (𝒚𝒕 ) 을 변환하는 Layer의 가중치 행렬 |
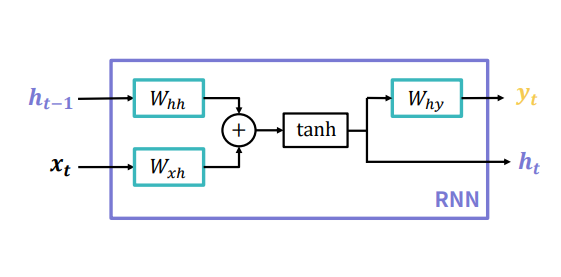
▶ Vanilla RNN 연산과정
1) 현재 입력값(xt)에 대한 새로운 hidden state 계산
ht-1 (이전 시점의 hidden state)와 xt(현재 입력값)을 각각 FC layer를 통과한 다음 더해서 tanh함수에 통과시킨다.


💡 tanh
: tangent hyperbolic 함수

RNN에서 tanh를 사용하는 이유
: 선형연산(더하고 곱하는 연산)은 딥러닝 모델 성능에 좋지 않은 성질이라 활성화 함수를 통하여 비선형성을 추가해준다.
많은 실험을 통해 RNN에서는 활성화 함수로 tanh를 사용하는게 성능이 좋다고 증명되어 tanh를 사용한다.
2) 현재 입력값(xt)에 대한 새로운 출력값 계산
앞서 계산한 hidden state를 이용한다.
앞에서 tanh을 통하여 비선형성이 추가되었기 때문에 따로 활성화함수를 사용하진 않는다.


▶ 시간순으로 보는 Vanilla RNN의 연산 과정

- 모델에 들어오는 각 시점의 데이터 𝑥𝑡마다 앞서 설명한 연산 과정을 수행한다.
- 입력값에 따라 반복해서 출력값과 hidden state를 계산한다.
- ⭐이전 시점에 생성된 hidden state를 다음 시점에 사용한다.
- ⭐각 시점에서 모두 동일한 RNN모델을 사용한다.
▶ Vanilla RNN의 의의
Hidden state의 의미
특정 시점 𝑡까지 들어온 입력값들의 상관관계나 경향성 정보를 압축해서 저장한다.
→ 모델이 내부적으로 계속 가지는 값이므로 일종의 메모리(Memory)로 볼 수 있다. (컴퓨터의 메모리와 일맥상통)
Parameter Sharing
Hidden state와 출력값 계산을 위한 FC Layer를 모든 시점의 입력값이 재사용한다.
→ FC Layer 세 개가 모델 파라미터의 전부
▶ Vanilla RNN의 종류
사용할 입력값과 출력값의 구성에 따라 여러 종류의 RNN이 존재한다.
다대일 (many-to-one)
: 출력값을 한 시점의 값만 사용
다대다 (many-to-many)
: 여러 시점의 입력값과 여러 시점의 출력값을 사용 (입력값과 출력값에 사용하는 시점의 개수는 같을 수도 있고 다를 수도 있다)


인코더-디코더 (Encoder-Decoder)
: 입력값들을 받아 특정 hidden state로 인코딩한 후, 이 hidden state로 새로운 출력값을 만드는 구조

▶ Vanilla RNN의 문제점
RNN은 출력값이 시간 순서에 따라 생성된다.
→ 각 시점의 출력값과 실제값을 비교하여 손실(Loss)값을 계산한다.
→ 역전파 알고리즘이 시간에 따라 작동한다. (Back-propagation Through Time = BPTT)

입력값의 길이가 매우 길어질 경우,
초기 입력값과 나중 출력값 사이에 전파되는 기울기 값이 매우 작아질 가능성이 높다.
기울기 소실(Vanishing Gradient) 문제가 발생하기 쉽다. ( = 장기 의존성(Long-term Dependency)을 다루기가 어렵다. )


이 글은 엘리스의 AI트랙 5기 강의를 들으며 정리한 내용입니다.
'개발공부 > 🤖 DL & ML' 카테고리의 다른 글
| [자연어 처리] 한국어 자연어 처리 및 문장 유사도 (0) | 2022.11.09 |
|---|---|
| [딥러닝 활용] 모델 서비스하기 (0) | 2022.11.09 |
| [자연어 처리] 텍스트 전처리 및 단어 임베딩 (0) | 2022.11.03 |
| [CNN] Convolutional Neural Network (0) | 2022.11.02 |
| [CNN] 이미지 데이터 (0) | 2022.11.01 |

프론트엔드 개발자 삐롱히의 개발 & 공부 기록 블로그