티스토리 뷰
1️⃣ 프로젝트와 데이터 분석
데이터 : 현실 세계의 일들을 관찰, 측정해서 얻은 값
정보 : 데이터를 처리해서 얻는 의미있는 값
데이터 분석 : 데이터를 활용하여 원하는 정보를 얻어내기 위한 일련의 과정
데이터 분석 프로젝트
문제정의 → 가설 설정 → 데이터 준비 → 데이터 분석 → 결과 정리
1) 문제 정의
현재 풀고자 하는 문제가 무엇인지를 명확히 정의
| 여행을 위해 가장 저렴한 가격으로 항공편을 예매하고자 한다. |
→ 문제 정의 : 언제 비행기 표를 예매해야 할까?
2) 가설 설정
문제를 해결하기 위한 데이터 분석의 토대인 가설 설정
- 문제와의 관련성 고려해야 한다.
- 정의한 문제 해결을 위한 가설 설정을 통해 필요한 데이터 셋과 데이터 분석 방향을 이해할 수 있다.
| 가설 1 - 비수기에 구매하면 가장 저렴 할 것이다. |
| 가설 2 - 새벽 시간에 구매하면 가장 저렴 할 것이다. |
💡 가설 설정 시 주의할 점
가설은 문제 해결을 위한 전체적인 방향 정도로만 생각해야한다.
가설이 문제의 정답인 것처럼 생각하고 분석을 진행한다면 데이터 분석 시각을 좁게 만들 위험성이 있다.
3) 데이터 준비
풀고 싶은 문제에 대한 정보를 담고 있는 데이터셋을 선정 (데이터 수집 및 전처리 과정)
| 다양한 시간대 별 항공권 가격 데이터 수집 및 처리 |
- 데이터 수집
: 설정한 가설을 바탕으로, 풀고 싶은 문제에 대한 정보를 담고 있는 데이터셋을 선정하고 수집한다.
- 데이터 전처리 ( = 데이터 정제 (Data Cleaning))
: 수집한 데이터 셋에 대해 이상치 제거, 중복 제거, 형태 변환 등의 초기 데이터(Raw Data) 전처리 시행한다.
4) 데이터 분석
본격적인 데이터 분석
- 데이터 분석 프로젝트의 성공여부는 얼마나 데이터를 이해하고 있느냐에 좌우된다.
- 탐색적 데이터 분석(EDA)을 통해 데이터의 특징을 파악한다.
- 파악한 특징을 바탕으로 설정한 가설을 검증한다.
💡 탐색적 데이터 분석(EDA)
Exploratory Data Analysis
: 데이터의 특징을 찾고, 숨겨진 패턴을 발견하는 과정
- 데이터 분석 단계에 해당하며 데이터 분포 확인, 변수간 관계 파악을 통해 전체 데이터의 특징을 발견하고 이해할 수 있다.
5) 결과 정리
분석 과정에서 알아낸 인사이트(Insight) 정리
- 데이터 특징(인사이트) 위주로 정리하기
- 설정한 가설이 옳았는지 검증 결과 정리하기
- 문제 해결을 위해 새롭게 발견한 해결 방안 정리하기
💡 인사이트(In + sight)
: 사물의 이면을 들여다보는 것
💡 의미 있는 데이터 분석
: 분석에서 그치는 것이 아닌 문제 해결을 위한 의미 있는 데이터 분석
- 인사이트를 알아내고, 문제를 해결하기 위한 개선 방향이나 해결방안을 얻어낸 것
- 그러기 위해서는 명확한 목표 설정과 목표에 맞는 흐름에 따른 데이터 분석을 진행해야 한다.
2️⃣ 데이터 분석 도구
데이터 분석을 위한 다양한 도구 존재

- 엑셀 : 데이터를 시각화하여 보기 편하고 유용한 함수들을 활용 가능
- 파이썬 : 범용적이며 데이터 분석을 위한 라이브러리 지원
- R : 데이터 분석을 위한 라이브러리 지원
- SPSS, SAS, ...
3️⃣ Jupyter Notebook 소개
Jupyter Notebook 이란?
웹 브라우저에서 코드를 작성하고 실행해볼 수 있는 오픈 소스 소프트웨어
- 셀 단위 코드 실행이 가능하여 데이터 분석, 머신러닝 등의 프로그램을 구현할 수 있다.

셀(Cell) 이란?
셀(Cell)은 기본 입력 단위
- 다양한 입력 모드와 종류를 가지고 있다.
1) 셀 모드
- 입력 모드와 명령 모드
- 기본 입력 모드로 시작, 이후 esc 키를 통해 명령모드 전환
2) 셀 종류
마크다운(Markdown) 셀과 코드(Code) 셀
💡 마크다운(Markdown)
: 깔끔한 문서를 편리하게 만드는 마법의 언어
- 개발과 관련된 문서 대부분 마크다운으로 작성한다.
- 깔끔한 문서 정리를 위한 다양한 문법 존재한다.
- Jupyter Notebook에서도 코드, 출력 결과에 대한 설명을 통한 데이터 분석을 깔끔하게 정리할 수 있다.
4️⃣ 데이터 분석 프로젝트를 진행해보자
주제
포켓몬 데이터 뭉치에서 전설의 포켓몬을 골라낼 수 있을까?
- "포켓몬"은 몬스터볼에 넣어서 주머니에 휴대하고 다닐 수 있는 몬스터를 말한다.
- 각 몬스터 마다 공격력, 방어력 등의 속성을 가진다.
- 속성에 따라 "일반 포켓몬"과 "전설 포켓몬"으로 분류된다.
- "전설의 포켓몬"은 일반적으로 보통 포켓몬보다 강력하며, 수량이 한정되어 있다.
- "전설의 포켓몬"은 일반 포켓몬과는 구분되는 속성을 가질 것으로 예상된다.
문제
일반 포켓몬과 전설 포켓몬이 혼합되어 있는 데이터 셋에서 데이터의 속성만을 보고 전설 포켓몬을 골라낼 수 있을까?
→ 전설 포켓몬이 어떤 특징을 가지고 있는지 탐색적 데이터 분석(EDA)를 통해 확인해보자
데이터 분석 준비하기
1) 필요한 모듈 import 하기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline # matplotlib 시각화 결과를 jupyter notebook에서 바로 확인하기 위해
2) 사용할 Dataset 로드하기
데이터 출처 : https://www.kaggle.com/datasets/abcsds/pokemon
data = pd.read_csv('Pokemon.csv') # 원본 데이터 보존용
pkemon = data # 아래에서 분석에 사용할 데이터는 pkemon 변수에 담기
3) 데이터 기본정보 확인 및 전처리하기
print(pkemon.shape)
pkemon.head()
# info를 통해 결측치가 있는지 판단
pkemon.info()
# 컬럼별 결측치 확인
pkemon.isnull().sum()
# 결측된 데이터 확인
pkemon[pkemon[결측치가 있는 컬럼].isnull()].head()
→ 해당 과정을 통해 'Type 2' 컬럼에서 결측치가 보이지만
'Type 2' 가 결측되어 있어도 다른 컬럼에 대한 정보는 모두 채워져 있기 때문에 바로 제거하진 않는다.
EDA (탐색적 데이터 분석)
1) 전설 포켓몬 데이터 셋 분리하기
# 전설 포켓몬 데이터 분리하기
legendary = pkemon[pkemon['Legendary'] == True].reset_index(drop=True)
print(legendary.shape)
legendary.head()
print("전체 데이터 중 전설 포켓몬 데이터 비율 : {}% ".format((legendary.shape[0]/pkemon.shape[0])*100))
→ 전체 데이터 개수가 800개 중 전설 포켓몬은 65개. 즉 전체 데이터의 8.125%밖에 존재하지 않음을 확인할 수 있다.
💡 reset_index(drop=True)
기존의 인덱스값을 버리고 조회된 데이터의 인덱스 초기화한다.
drop=True를 하지 않으면 이전 인덱스가 새로운 컬럼으로 생성된다.
# 일반 포켓몬 데이터 분리하기
ordinary = pkemon[pkemon['Legendary'] == False].reset_index(drop=True)
print(ordinary.shape)
ordinary.head()
2) 모든 컬럼 살펴보기
print(len(pkemon.columns))
pkemon.columns
2-1. '#' 컬럼 (포켓몬 id number)
# '#'(id number)값의 갯수 확인
len(pkemon['#'].unique())→ 총 데이터가 800개 인데 id number값은 그보다 작기 때문에 고유값이 아니고 중복값을 가지는 데이터가 있다.
# 같은 '#'(id number)값을 가지는 데이터 빈도 수 확인
pkemon['#'].value_counts()→ id number가 479인 경우가 가장 빈도수가 높다.
# id number 479 확인
pkemon[pkemon['#']==479]
pkemon[pkemon['#']==386]→ 'Rotom' 이라고 하는 단어가 앞에 붙어 있는 포켓몬들이 동일한 id number로 존재하는 것이 확인된다.
→ 다른 중복값들도 이와 같은 패턴인지 확인해본다.
→ 다른 중복값도 동일한 단어로 이름이 시작하지만 완전히 그렇다고 속단하기는 어렵다.
2-2. 'Name' 컬럼 (포켓몬 이름)
# 'Name'값의 갯수 확인
len(pkemon['Name'].unique())
→ 'Name' 컬럼의 고유 값의 개수는 데이터셋 전체 크기와 동일하므로, 모든 포켓몬의 이름이 동일하지 않음을 의미한다.
# names : 이름이 비슷한 전설의 포켓몬들
n1, n2, n3, n4, n5 = legendary[3:6], legendary[14:24], legendary[25:29], legendary[46:50], legendary[52:57]
names = pd.concat([n1, n2, n3, n4, n5]).reset_index(drop=True)
# set_names : 이름이 세트로 지어져있는 포켓몬들
sn1, sn2 = names[:13], names[23:]
set_names = pd.concat([sn1, sn2]).reset_index(drop=True)
set_names→ "MewTwo", "Latias", "Latios" 등의 이름의 앞에 성이 붙여진다.
→ 포켓몬 원형이 전설 포켓몬일 경우 해당 포켓몬의 성이 붙으면 그 포켓몬도 전설 포켓몬일 가능성이 높다.
전설 포켓몬과 일반 포켓몬의 이름 길이에 어떤 특징이 있는지 보기 위해 이름 길이 컬럼 생성 후 그래프 작성
# legendary에 이름 길이 컬럼 생성
legendary['name_count'] = legendary['Name'].apply(lambda i: len(i))
legendary.head()
# ordinary에 이름 길이 컬럼 생성
ordinary['name_count'] = ordinary['Name'].apply(lambda i: len(i))
ordinary.head()
# 그래프 출력하기
plt.figure(figsize=(18,10))
plt.subplot(211)
sns.countplot(data=legendary, x="name_count")
plt.title("Legendary")
plt.subplot(212)
sns.countplot(data=ordinary, x="name_count")
plt.title("Ordinary")
plt.show()
→ 전설의 포켓몬은 16 이상의 긴 이름을 가진 포켓몬이 많고, 일반 포켓몬은 10 이상의 길이를 가지는 이름의 빈도가 아주 낮다.
→ 하지만 y축 값을 잘 고려해야 한다. 그래프 상에서는 많아보여도 값 자체는 전설 포켓몬은 총 65개밖에 되지 않는다.
→ 그래프로는 비교가 어려우니 비율로 확인한다.
# 전설 포켓몬의 이름이 10 이상일 확률
print(round(len(legendary[legendary["name_count"] > 9]) / len(legendary) * 100, 2), "%")
# 일반 포켓몬의 이름이 10 이상일 확률
print(round(len(ordinary[ordinary["name_count"] > 9]) / len(ordinary) * 100, 2), "%")→ 전설 포켓몬의 이름이 10 이상일 확률은 41%, 일반 포켓몬의 이름이 10 이상일 확률은 약 16% 이다.
→ 이는 아주 큰 차이이므로 legendary인지 아닌지를 구분하는데에 큰 의미를 가진다고 할 수 있다.
2-3. 'Type 1', 'Type 2' 컬럼 (포켓몬 속성)
# 임의의 2개의 데이터 확인
pkemon.loc[[6, 10]]→ 포켓몬이 가지는 속성은 기본적으로 하나. 또는 최대 두 개
→ 'Type 2'에만 결측값이 존재하던 이유를 추측해볼 수 있다.
# 속성의 고유값 갯수
len(pkemon['Type 1'].unique()), len(pkemon['Type 2'].unique())
# 속성의 차이점
set(pkemon['Type 2']) - set(pkemon['Type 1']) # {nan}→ 두 고유값의 차이는 Nan 값
→ 포켓몬의 속성은 18가지. Type1, Type2 모두 같은 종류의 데이터가 들어가 있다.
# types : 모든 포켓몬 타입 리스트
types = list(pkemon["Type 1"].unique())
print(len(types))
print(types)
Type을 하나만 가지고 있는 포켓몬의 수 = 'Type 2'가 결측값인 수
len(pkemon[pkemon['Type 2'].isna()])
Type을 2개 가지고 있다면 전설 포켓몬일 확률이 높은지 분석
legendary['Type 2'].notnull().sum()
'Type 1' 의 일반 포켓몬과 전설 포켓몬의 속성 분포 시각화
plt.figure(figsize=(18,10))
plt.subplot(211)
sns.countplot(data=pkemon, x='Type 1', hue="Legendary", order=types)
plt.title('All Poketmons')
plt.subplot(212)
sns.countplot(data=legendary, x='Type 1', order=types)
plt.title('Legendary Poketmon')
plt.show()
'Type 1'의 각 속성별 전설 포켓몬이 몇 % 있는지 분석
pd.pivot_table(pkemon, index="Type 1", values="Legendary").sort_values(by=["Legendary"], ascending=False).T
→ 'Type 1' 이 Flying 속성이면 전설 포켓몬일 확률이 높다.
'Type 2' 의 일반 포켓몬과 전설 포켓몬의 속성 분포 시각화
plt.figure(figsize=(18,10))
plt.subplot(211)
sns.countplot(data=pkemon, x='Type 2', hue="Legendary", order=types)
plt.title('All Poketmons')
plt.subplot(212)
sns.countplot(data=legendary, x='Type 2', order=types)
plt.title('Legendary Poketmon')
plt.show()
'Type 2'의 각 속성별 전설 포켓몬이 몇 % 있는지 분석
pd.pivot_table(pkemon, index="Type 2", values="Legendary").sort_values(by=["Legendary"], ascending=False).T
→ 'Type 1' 보다 낮은 수치이나 'Type 2' 가 FIre 일 경우가 가장 높다.
2-4. 'Total' 컬럼 (모든 스탯의 총합)
전설 포켓몬은 일반 포켓몬 보다 강한 특징을 갖기 때문에 종합치가 높을 것이다.
stats = ["HP", "Attack", "Defense", "Sp. Atk", "Sp. Def", "Speed"]
모든 포켓몬과 전설 포켓몬의 Total 값 분포를 산점도를 통해 시각화
plt.figure(figsize=(16, 8))
plt.scatter(data=pkemon, x='Type 1', y='Total')
plt.scatter(data=legendary, x='Type 1', y='Total')
plt.show()
→ 전설 포켓몬은 일반 포켓몬 보다 종합치가 높다. (O)
전설 포켓몬의 속성 Total 값 확인
plt.figure(figsize=(8, 6))
plt.scatter(data=legendary, x='Total', y='Type 1')
plt.show()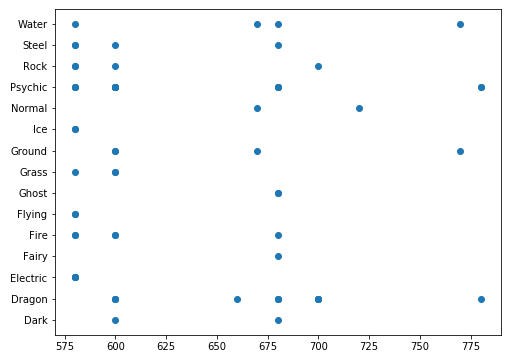
→ 전설 포켓몬의 Total 값들이 중복되는 값이 많다.
전설 포켓몬의 Total값들의 고유값 확인 및 그래프로 시각화
# 전설 포켓몬이 가지는 Total 고유값
print(legendary['Total'].unique())
len(legendary['Total'].unique()) # 9
# 전설 포켓몬이 가지는 Total값 갯수 시각화
plt.figure(figsize=(8,6))
sns.countplot(data=legendary, x='Total')
plt.show()
→ Total값이 580인 전설 포켓몬이 많다.
→ 약 7.22마리(65/9)는 같은 Total 스탯값을 가진다.
일반 포켓몬의 Total값들의 고유값 확인 및 그래프로 시각화
# 일반 포켓몬이 가지는 Total 고유값
print(ordinary['Total'].unique())
len(ordinary['Total'].unique())
# 일반 포켓몬이 가지는 Total값 갯수 시각화
plt.figure(figsize=(8,6))
sns.countplot(data=ordinary, x='Total')
plt.show()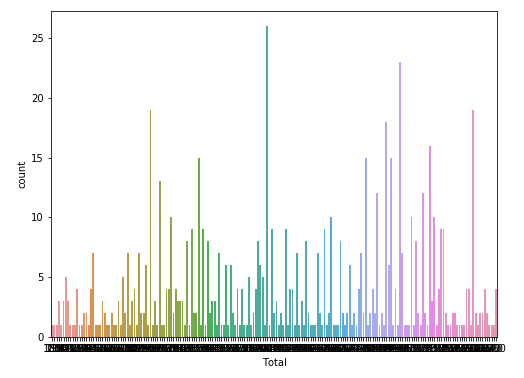
→ 약 3.77마리(65/9)는 같은 Total 스탯값을 가진다.
→ Total 스탯값이 전설 포켓몬의 특징이 될 수 있다. (위 9개의 Total 스탯값을 가지면 전설 포켓몬일 확률이 높다.)
2-5. 각 Sataus(HP, Attack, Defense, Sp.Atl, Sp.Def, Speed) 컬럼
# 6가지 스탯 값 시각화
plt.figure(figsize=(16,8))
plt.subplot(231)
plt.scatter(data=pkemon, y="Total", x="HP")
plt.scatter(data=legendary, y="Total", x="HP")
plt.title('HP')
plt.subplot(232)
plt.scatter(data=pkemon, y="Total", x="Attack")
plt.scatter(data=legendary, y="Total", x="Attack")
plt.title('Attack')
plt.subplot(233)
plt.scatter(data=pkemon, y="Total", x="Defense")
plt.scatter(data=legendary, y="Total", x="Defense")
plt.title('Defense')
plt.subplot(234)
plt.scatter(data=pkemon, y="Total", x="Sp. Atk")
plt.scatter(data=legendary, y="Total", x="Sp. Atk")
plt.title('Sp. Atk')
plt.subplot(235)
plt.scatter(data=pkemon, y="Total", x="Sp. Def")
plt.scatter(data=legendary, y="Total", x="Sp. Def")
plt.title('Sp. Def')
plt.subplot(236)
plt.scatter(data=pkemon, y="Total", x="Speed")
plt.scatter(data=legendary, y="Total", x="Speed")
plt.title('Speed')
plt.show()
HP, Defense, Sp.Def
→ 종합치는 전설 포켓만 보다 낮지만 특정 스탯(HP, Defense, Sp.Def)만 월등히 높은 일반 포켓몬들이 몇몇 있다.
Attack, Sp.Atk, Speed
→ Total과 거의 비례하는 분포가 나타난다.
2-.6 Generation(포켓몬 세대) 컬럼
# 세대별 데이터 시각화
plt.figure(figsize=(8,6))
plt.subplot(211)
sns.countplot(data=pkemon, x='Generation', hue='Legendary')
plt.title('All Poketmon')
plt.subplot(212)
sns.countplot(data=legendary, x='Generation')
plt.title('Legendary Poketmon')
plt.show()
→ 전설 포켓몬은 3세대부터 많아졌다가 6세대에 다시 많이 줄어들었다.

이 글은 엘리스의 AI트랙 5기 강의를 들으며 정리한 내용입니다.
'개발공부 > 🎅 Python' 카테고리의 다른 글
| [Python] Matplotlib 데이터 시각화 (0) | 2022.09.28 |
|---|---|
| [Python] Pandas 심화 알아보기 (0) | 2022.09.27 |
| [Python] Pandas 기본 알아보기 (0) | 2022.09.27 |
| [Python] NumPy 사용해보기 (0) | 2022.09.24 |
| [Python] TED 강연을 통해 접해 보는 복잡한 형태의 데이터 (0) | 2022.09.23 |

프론트엔드 개발자 삐롱히의 개발 & 공부 기록 블로그