티스토리 뷰
1️⃣ 조건으로 검색하기
데이터 프레임에서 각 컬럼마다 조건을 충족하는 값만 추출할 수 있다.
Numpy의 마스킹 연산처럼 조건식을 직접 쓸 수도 있고, query() 함수를 이용하는 방법도 있다.
1) masking 연산
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
df["A"] < 0.5
2) 조건에 맞는 DataFrame row 추출
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
# 마스킹 연산
df[(df["A"] < 0.5) & (df["B"] > 0.3)]
# query()
df.query("A < 0.5 and B > 0.3")
3) 문자열 조건 검색
df["Animal"].str.contains("Cat")
df.Animal.str.match("Cat")
2️⃣ 함수로 데이터 처리하기
apply를 통해서 함수로 데이터를 다룰 수 있다.
df = pd.DataFrame(np.arange(5), columns=["Num"])
def square(x):
return x**2
df["Num"].apply(square)
# lambda 표현식으로
df["Square"] = df.Num.apply(lambda x: x ** 2)
예시)
df = pd.DataFrame(columns=["phone"])
df.loc[0] = "010-1234-1235"
df.loc[1] = "공일공-일이삼사-1235"
df.loc[2] = "010.1234.일이삼오"
df.loc[3] = "공1공-1234.1이3오"
df["preprocess_phone"] = ''
def get_preprocess_phone(phone):
mapping_dict = {
"공": "0",
"일": "1",
"이": "2",
"삼": "3",
"사": "4",
"오": "5",
"-": "",
".": "",
}
for key, value in mapping_dict.items():
phone = phone.replace(key, value)
return phone
df["preprocess_phone"] = df["phone"].apply(get_preprocess_phone)
replace()
apply 기능에서 데이터 값만 대체
df.Sex.replace({"Male": 0, "Female": 1})
# Male은 0, Female은 1로 변경 / series데이터 반환
df.Sex.replace({"Male": 0, "Female": 1}, inplace=True)
# inplace=Ture 하면 series데이터를 반환하지 않고 df를 바로 수정한다.
3️⃣ 그룹으로 묶기
간단한 집계를 넘어서서 조건부로 집계하고 싶은 경우,
groupby()를 통해 그룹으로 묶고 sum(), min()등으로 조건부 집계가 가능하다.
groupby()
: 키 값을 기준으로 그룹 생성
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [1, 2, 3, 1, 2, 3],
'data2': np.random.randint(0, 6, 6)
})
df.groupby('key') # <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x10e3588>
df.groupby('key').sum()
df.groupby(['key','data1']).sum()

aggregate()
: groupby를 통해서 집계를 한번에 계산하는 방법
df.groupby('key').aggregate([min, np.median, max])
df.groupby('key').aggregate({'data1': min, 'data2': np.sum})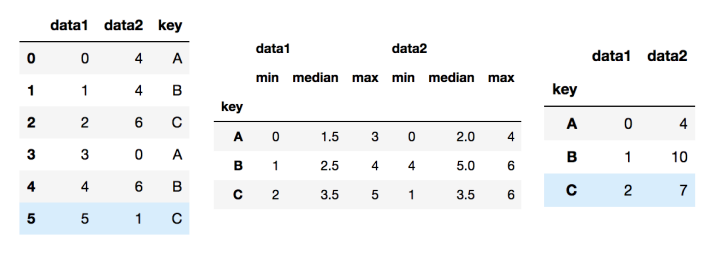
💡 agregate 메소드에 함수를 매개변수로 넣어줄 때,
min, max, mean, count 등의 특정 함수들은 문자열 형태로 넘겨줄 수 있다.
df.groupby('key').aggregate([min, np.median, max])
df.groupby('key').aggregate(['min', np.median, 'max'])
filter()
: groupby를 통해서 그룹 속성을 기준으로 데이터 필터링
def filter_by_mean(x):
return x['data2'].mean() > 3
df.groupby('key').mean()
df.groupby('key').filter(filter_by_mean)
apply()
: groupby를 통해서 묶인 데이터에 함수 적용
df.groupby('key').apply(lambda x: x.max() - x.min())
get_group()
: groupby로 묶인 데이터에서 key값으로 데이터 추출
df = pd.read_csv("./univ.csv")
df.head()
df.groupby("시도").get_group("충남")
len(df.groupby("시도").get_group("충남")) # 94
4️⃣ MultiIndex & pivot_table
MultiIndex
- 인덱스를 계층적으로 만들 수 있다.
df = pd.DataFrame(
np.random.randn(4, 2),
index=[['A', 'A', 'B', 'B'], [1, 2, 1, 2]],
columns=['data1', 'data2']
)
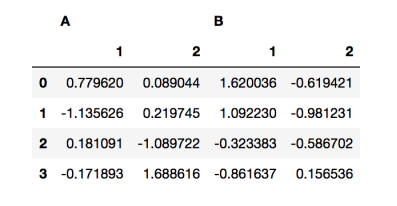
- 열 인덱스도 계층적으로 만들 수 있다.
df = pd.DataFrame(
np.random.randn(4, 4),
columns=[["A", "A", "B", "B"], ["1", "2", "1", "2"]]
)
- 다중 인덱스 컬럼의 경우 인덱싱은 계층적으로 한다.
df["A"]
df["A"]["1"]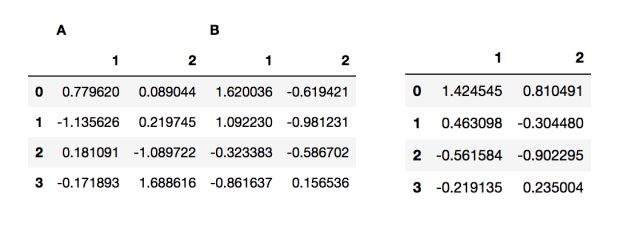
- 인덱스 탐색의 경우에는 loc, iloc를 사용 가능하다.
pivot_table
데이터에서 필요한 자료만 뽑아서 새롭게 요약, 분석 할 수 있는 기능
(= 엑셀에서의 피봇 테이블)
- Index : 행 인덱스로 들어갈 key
- Column : 열 인덱스로 라벨링될 값
- Value : 분석할 데이터
예시1) 타이타닉 데이터에서 성별과 좌석별 생존률 구하기

df.pivot_table(
index='sex', columns='class', values='survived',
aggfunc=np.mean
)
예시2)
df.pivot_table(index="월별", columns='내역', values=["수입", '지출'])

이 글은 엘리스의 AI트랙 5기 강의를 들으며 정리한 내용입니다.
'개발공부 > 🎅 Python' 카테고리의 다른 글
| [Python] 데이터 분석 프로젝트 가이드 (0) | 2022.09.29 |
|---|---|
| [Python] Matplotlib 데이터 시각화 (0) | 2022.09.28 |
| [Python] Pandas 기본 알아보기 (0) | 2022.09.27 |
| [Python] NumPy 사용해보기 (0) | 2022.09.24 |
| [Python] TED 강연을 통해 접해 보는 복잡한 형태의 데이터 (0) | 2022.09.23 |

프론트엔드 개발자 삐롱히의 개발 & 공부 기록 블로그